Transformer
2017,Google
Ashish Vaswani,印度裔的
512维,8个heads,每个64维
位置编码相关
理解Position Embedding的经典例子:”你爱我“ 和 ”我爱你“
为序列中的每个位置生成一个独特的向量
位置编码的设计原则
- 唯一性:每个位置应有唯一的编码。
- 相对位置的感知:编码应能反映词与词之间的相对距离(如相邻词的编码应相似)。
- 可扩展性:支持比训练时更长的序列(如Transformer原论文使用固定公式而非可学习参数)。
原论文使用正弦和余弦函数的组合生成位置编码:
其中:
pos:词的位置i:编码向量的维度索引- :模型的隐藏层维度(与词向量维度相同,=512)
除了符合那几个原则,这种编码还有几个妙处:
-
捕捉了相对位置的线性关系:对任意固定的偏移量 k,存在线性变换矩阵 M,使得:
-
相邻词的距离为定值
-
多频率编码:不同维度对应不同波长,能捕捉不同粒度的位置信息(高频维度区分近距离,低频维度区分远距离)
TODO:Transformer-XL、旋转位置编码(RoPE)
基于transformer的预训练模型可以分为4类
编码器的
解码器的
seq2seq的
文本-视觉的
GPT
Generative Pre-trained Transformer(GPT1),2018
Decoder-Only
后续发展 2020-GPT3,2022-ChatGPT,2023-GPT4,2024-GPTo1
GPT3 small参数的计算?
3b1b的视频是这么算的:
50257 tokens 每个词嵌入12288维 50257x12288
解嵌入 Matrix 50257x12288
温度即对softmax的调整
W_Q W_K 128x12288 = 1572864
Q K 128xL
QK^T LxL
W_V 12288x12288 实际并非如此多参数,是一个12288x128矩阵乘上一个128x12288的矩阵
V 12288xL
V·softmax(Q^KT) 12288xL
GPT3 96头 96层 总参数量12288x128x4x96x96=603,979,776
此外还要计算MLP的参数量,MLP每次先升维到49152再降回去
故MLP参数量(不算偏置项、Layer Norm)12288x49152x2x96
最终合起来是1750亿参数量
多头自注意力机制那里,
注意力机制 输入: 向量 ,形状为 输出: 向量 QKV 参数: 变换为 QKV 的参数矩阵,尺寸都为 ,含义为(向量维度,注意力头维度) 有 个 头 转换到 维度后,还有一个矩阵负责转换为 :这个转换矩阵的维度为 总参数量: 一般而言,,所以
GPT 的预训练任务:自回归 / 因果语言建模(Auto-regressive / Causal Language Modeling, CLM)
模型在预训练阶段的目标是: 给定前面的所有词,预测下一个词
BERT
Bidirectional Encoder Representation from Transformers,2018,Google
Encoder-Only,有强大的理解能力,但无法自主生成文本。
作者分别用12层(d=768)和24层(d=1024)Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
BERT-Base的参数计算(未计算LayerNorm参数)
总参数量:约110M(1.1 亿)
1️⃣ Embedding 层(Token + Position + Segment)
- Token Embeddings: 30522 x 768
- Position Embeddings: 512 x 768
- Segment Embeddings: 2 x 768(只在做NSP的时候用)
- 词表大小(30522)
- 隐藏层维度(768)
- 最大序列长度(512)
总计 23.8M
2️⃣ Transformer 编码器层(共 12 层)
- Query、Key、Value 的权重矩阵:3 x 768 x 768
- 输出投影矩阵:768 × 768
前馈神经网络(Feed-Forward Network, FFN),也是先升维再降维,768x3072x2
总计 (4x768x768+768x3072x2)x12 = 84.9M
在 BERT 中,多头自注意力机制被用来允许模型在不同的表示子空间中并行地执行注意力操作。采用隐藏层维度 (H) 分割:对于每个注意力头,输入向量首先会被分割成较小的块(即降维),每个头处理输入向量的一个子集。例如,在 BERT-Base 中,隐藏层大小为 768 维,如果有 12 个注意力头,则每个头处理的是 (768 / 12 = 64) 维的子向量。
3️⃣ Pooler 层(用于 [CLS] 向量输出)
- 一个全连接层 768 × 768 = 0.59M
BERT是用了Transformer的encoder侧的网络,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token,此即为双向的体现,而并非想Bi-LSTM那样把句子倒序输入一遍。在BERT之前是GPT,GPT使用的是Transformer的decoder侧的网络,GPT是一个单向语言模型的预训练过程,更适用于文本生成,通过前文去预测当前的字。(就是那个mask与否的问题)
Embedding由三种Embedding直接求和而成:
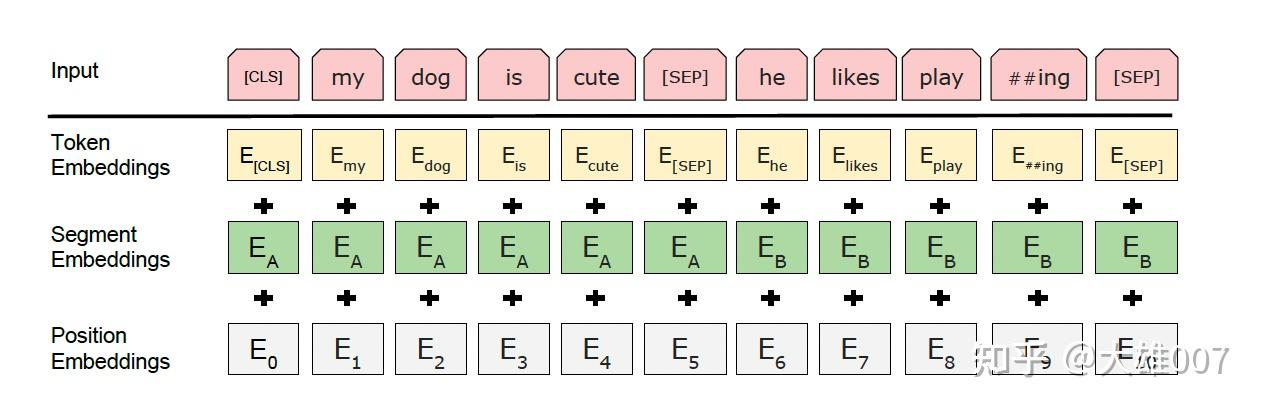
-
Token Embeddings是词向量,第一个单词是CLS标志,其对应的特征用于之后的分类任务
(GPT uses a sentence separator ([SEP]) and classifier token ([CLS]) which are only introduced at fine-tuning time; BERT learns [SEP], [CLS] and sentence A/B embeddings during pre-training)
playing 会切割成 play 和 ##ing,这叫做WordPiece tokenization。解决未登录词的常见方法,还使得Bert 在处理英文文本时只需要 30522 个词。
Token Embeddings 层会将每个词转换成 768 维向量,例子中 11 个Token 会被转换成一个 (11, 768) 的矩阵或 (1, 11, 768) 的张量。
-
Segment Embeddings用来区别两种句子,预训练除了LM,还需要做判断两个句子先后顺序之类的的分类任务。
前一个句子的每个token都用0表示,后一个句子的每个token都用1表示。如”[CLS] my dog is cute [SEP] he likes play ##ing [SEP]“ 表示成”0 0 0 0 0 0 1 1 1 1 1“。 如果输入仅仅只有一个句子,那么它的segment embedding就是全0。 这也是一个(11, 768)维的张量。
-
Position Embeddings和之前文章中的Transformer不一样,不是三角函数计算的而是学习出来的。
BERT 中处理的最长序列是 512 个 Token,长度超过 512 会被截取,BERT 在各个位置上学习一个向量来表示序列顺序的信息编码进来,这意味着 Position Embeddings 实际上是一个 (512, 768) 的 lookup 表,表第一行是代表第一个序列的每个位置,第二行代表序列第二个位置。
以下为BERT使用的预训练任务:
-
Task 1: Masked Language Model(MLM)
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。训练其对应输出是原单词。
【后面有人提出SpanBERT,预测一个范围内的被MASK的文本】
-
Task 2: Next Sentence Prediction(NSP)
将两个句子A和B链接起来,预测原始文本中句子B是否排在句子A之后。
具体训练的时候,50%的输入对在原始文档中是前后关系,另外50%中是从语料库中随机组成的,并且是与第一句断开的。最后用一个简单的分类层将[CLS]标记的输出变换为 2×1 形状的向量。
在训练BERT模型时,Masked LM和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
这个Task 2后续应用不多
BERT的微调(Fine-tunning)
-
对于不同的下游任务,我们仅需要对BERT不同位置的输出进行处理即可,或者直接将BERT不同位置的输出直接输入到下游模型当中。具体如下:
- 对于情感分析等单句分类任务,可以直接输入单个句子(不需要[SEP]分隔双句),将[CLS]的输出直接输入到分类器进行分类
- 对于句子对任务(句子关系判断任务),需要用[SEP]分隔两个句子输入到模型中,然后同样仅须将[CLS]的输出送到分类器进行分类
- 对于问答任务,将问题与答案拼接输入到BERT模型中,然后接两个分类器分别输出答案开始和结束的位置
- 对于命名实体识别任务,对每个位置的输出进行分类即可,如果将每个位置的输出作为特征输入到CRF将取得更好的效果。
TODO: CRF 条件随机场
- 对于常规分类任务,在 Transformer 的输出之上加一个分类层
T5
Transfer Text-to-Text Transformer (2019)
Encoder-Decoder
把所有任务统一为text to text的任务
- Prefix language modeling(前缀语言建模):输入部分文本,目标是预测剩余的文本。例如,输入“Thank you for inviting”,目标是预测“me to your party last week”。
- BERT-style(BERT风格):MLM
- Deshuffling(解乱序):输入被打乱顺序的文本,目标是恢复原始顺序。例如,输入“party me for your to . last fun you inviting week Thank”,目标是恢复为“Thank you for inviting me to your party last week”。
- I.i.d. noise, mask tokens(独立同分布噪声,掩码词):随机掩码一些词,然后预测这些被掩码的词。例如,输入“Thank you
me to your party week .”,目标是预测被掩码的词。 - I.i.d. noise, replace spans(独立同分布噪声,替换片段):随机替换一些片段,然后预测这些被替换的片段。例如,输入“Thank you
me to your party week .”,目标是预测被替换的片段“ for inviting last ”。 - I.i.d. noise, drop tokens(独立同分布噪声,删除词):随机删除一些词,然后预测这些被删除的词。例如,输入“Thank you me to your party week .”,目标是预测被删除的词“for inviting last”。
- Random spans(随机片段):随机选择一些片段进行掩码或替换,然后预测这些被处理的片段。例如,输入“Thank you
to week .”,目标是预测被处理的片段“ for inviting me your party last ”。
【T5在机器翻译效果不好?训练集问题】
BART
Bidirectional and Auto-Regressive Transformers(2019,facebook AI)
建立在标准的seq2seq Transformer model的基础之上,旨在解决一系列文本生成任务。
不同于BERT仅关注理解型任务,BART设计了一个去噪自编码器,该编码器首先对输入文本进行部分破坏(例如删除、替换、重新排序等),然后训练模型尝试恢复原始文本。
XLNet
Google Brain, CMU(卡内基梅隆大学) 2019
也是预训练语言模型,旨在结合自回归(AR)和自编码(AE)模型的优势,突破BERT等模型的局限性。
BERT属于自编码器(AE)语言模型。AE语言模型的优点是它可以在向前和向后两个方向上看到上下文。但是AE语言模型也有其不足之处。它在预训练中使用了
[MASK],但是这种人为的符号在finetune的时候在实际数据中时没有的,导致了pretraining — finetune的不一致。另一个缺点是它假设预测的(屏蔽的)tokens是相互独立的。
其核心创新包括:
-
重排列语言建模(Permutation Language Modeling, PLM):通过随机排列输入序列的顺序,使模型在自回归框架下捕获双向上下文信息,避免了BERT中因掩码(Mask)导致的预训练与微调不一致问题。
核心机制:对输入序列的所有可能排列顺序进行采样,模型根据当前排列顺序预测每个位置的词。例如,序列
[x1, x2, x3, x4]可能被排列为[x3, x2, x4, x1],预测x2时仅能看到x3,而预测x1时能看到所有其他词。 -
双流自注意力机制(Two-Stream Self-Attention):分离内容流(Content Stream)和查询流(Query Stream),确保模型在预测时既能利用上下文信息,又不泄露当前位置的内容。
- 内容流:包含词的内容和位置信息,用于建模上下文,与传统Transformer类似。
- 查询流:仅包含位置信息,用于预测当前词时避免信息泄漏。例如,预测x3时,查询流仅利用其位置编码生成注意力权重,确保模型无法直接访问x3的内容。
- Transformer-XL架构:引入长文本建模能力,通过分段循环机制(Segment Recurrence)和相对位置编码(Relative Positional Encoding)处理长序列依赖。
- 分段循环机制:缓存前一段的隐状态,解决长文本依赖的截断问题,使模型能跨段建模(如文档级任务)。
- 相对位置编码:用相对距离替代绝对位置编码,增强模型对位置关系的鲁棒性。
但这个模型后续评价不佳。
FFN相关
原始的Transformer结构中,每一层包含multi-head self-attention block (MHSA) 和一个FFN。FFN的本质就是一个token-wise的升维-过激活-降回原来维度的MLP。其输入是MHSA输出的(n, d)维的序列表示x,其中n为序列中的token数目,d为隐藏层维度,设中间层维度为d’(通常大于d,常见实现中d’ = 4d),其权重为升维矩阵W₁ ∈ ℝᵈˣᵈ’ 和降维矩阵W₂ ∈ ℝᵈ’ˣᵈ,激活函数为σ。为简便起见忽略bias项。则FFN层的前向过程为:
原始的Transformer和BERT模型中取,即,其中ψ为标准正态分布的密度
Benchmark: GLUE
(General Language Understanding Evaluation,2018)
用于评估自然语言处理(NLP)模型通用语言理解能力的BenchMark
GLUE 子任务
(1) Corpus of Linguistic Acceptability (CoLA)
- 目标:判断句子是否符合语法(二元分类)。
- 指标:Matthew’s Correlation Coefficient(尤其适合用来评估不平衡数据集上的二分类器性能)
(2) Stanford Sentiment Treebank (SST-2)
- 目标:句子情感分类(正面/负面)。
- 指标:准确率(Accuracy)。
(3) Microsoft Research Paraphrase Corpus (MRPC)
- 目标:判断句子对是否语义等价(释义检测)。
- 指标:准确率(Accuracy)和 F1 分数。
(4) Quora Question Pairs (QQP)
- 目标:判断两个问题是否语义相同(重复问题检测)。
- 指标:准确率(Accuracy)和 F1 分数。
(5) Semantic Textual Similarity Benchmark (STS-B)
- 目标:评估句子对的语义相似度(1-5 分回归任务)。
- 指标:Pearson/Spearman 相关系数。
(6) Multi-Genre Natural Language Inference (MNLI)
- 目标:判断前提(premise)与假设(hypothesis)的关系(蕴含/矛盾/中立)。
- 变体:MNLI-m(匹配领域)、MNLI-mm(不匹配领域)。
- 指标:准确率(Accuracy)。
(7) Question-Answering NLI (QNLI)
- 目标:判断问题与文本段落是否包含答案(二元分类,改编自 SQuAD)。
- 指标:准确率(Accuracy)。
(8) Recognizing Textual Entailment (RTE)
- 目标:二分类版本的文本蕴含任务(判断前提是否蕴含假设)。
- 指标:准确率(Accuracy)。
(9) Winograd NLI (WNLI)
- 目标:共指消解任务(判断代词指代是否合理)。
- 指标:准确率(Accuracy)。
大模型中的tokenizer
分词器
按照不同尺度可以分为:
- word base
- character base
- subword tokenization
以下均为subword tokenization:
-
BPE(Byte Pair Encoding)
GPT使用的分词方法 不断合并
-
WordPiece
BERT使用的分词方法。和BPE类似也是每次从词表中选出两个子词合并成新的子词,但是是基于概率生成新的subword而不是下一最高频字节对。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。
-
Unigram LM
-
SentencePiece
RLHF
基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,简称 RLHF)
从2016年开始,随着深度学习技术的发展以及大规模数据标注能力的提升,逆强化学习(Inverse Reinforcement Learning, IRL)与深度强化学习开始结合。2017年,DeepMind发表了《Deep Reinforcement Learning from Human Preferences》这篇论文,展示了如何从人类偏好中学习复杂游戏策略,这是RLHF的一个重要里程碑。
InstructGPT中的RLHF
自2021年起,OpenAI的InstructGPT和ChatGPT等项目将RLHF推向主流,证明了其在语言模型对齐中的有效性。通过这一方法,模型能够更好地理解和回应人类的需求和偏好。
其训练流程通常包括三个阶段:
-
监督微调(Supervised Fine-tuning,SFT)
雇佣40名标注人员完成prompt的标注。 此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
-
奖励模型训练(Reward Model Training):
模型生成出若干结果(可以通过beam search等方法),通过人工为其排序,例如D>C>A=B,可以得到标注的排序pair;基于标注的排序结果,训练一个Reward Model(输出打分)
具体来说,对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
-
强化学习微调(PPO)
使用强化学习(如PPO算法)让模型在生成回答时最大化奖励模型的打分,从而使得模型输出更符合人类喜好。
PEFT技术
参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
适用于大语言模型(LLMs)的适配任务。
Adapter-Tuning
最早是2019年提出
固定Transformer的全部参数,然后在Transformer的每一个Block里嵌入一些新初始化的Adapter Network。
Prefix-Tuning
最早2021提出
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In ACL/IJCNLP 2021, pages 4582–4597. Association for Computational Linguistics.
保持预训练语言模型参数固定(frozen),而只需要在task-specific vector(称为prefix)上进行优化。
这可以看作一种soft prompt。和固定模板文字的hard prompt相对。
以下为论文内容
微调是利用大型预训练语言模型执行下游任务的事实上的方法。然而,它修改了所有语言模型参数,因此需要为每个任务存储一个完整的副本。在本文中,我们提出了前缀微调,这是一种轻量级的替代微调方法,适用于自然语言生成任务,它保持语言模型参数不变,但优化了一个小的连续任务特定向量(称为前缀)。前缀微调从提示中汲取灵感,允许后续的标记关注这个前缀,就像它是“虚拟标记”一样。我们将前缀微调应用于GPT-2进行表格到文本的生成,并应用于BART进行摘要。我们发现,通过仅学习0.1%的参数,前缀微调在完整数据设置下获得可比的性能,在低数据设置下优于微调,并且对训练期间未见过的主题示例具有更好的外推能力。
1 引言
微调是使用大型预训练语言模型(LMs)执行下游任务(例如,摘要)的主流范式,但它需要更新和存储LM的所有参数。因此,为了构建和部署依赖于大型预训练LM的NLP系统,目前需要为每个任务存储LM参数的一个修改后的副本。鉴于当前LM的巨大规模,这可能非常昂贵;例如,GPT-2有7.74亿个参数,而GPT-3有1750亿个参数。解决这个问题的一种自然方法是轻量级微调,它冻结大部分预训练参数,并用小型可训练模块增强模型。例如,适配器微调(Rebuffi等人,2017;Houlsby等人,2019)在预训练语言模型的层之间插入额外的任务特定层。适配器微调在自然语言理解和生成基准上表现出有希望的性能,在仅添加大约2-4%的任务特定参数的情况下达到与微调相当的性能(Houlsby等人,2019;Lin等人,2020)。
在极端情况下,GPT-3(Brown等人,2020)可以在没有任何任务特定微调的情况下部署。相反,用户在任务输入前附加一个自然语言任务指令(例如,TL;DR用于摘要)和一些示例;然后从LM生成输出。这种方法被称为上下文学习或提示。
在本文中,我们提出了前缀微调,这是一种轻量级的替代微调方法,适用于自然语言生成(NLG)任务,灵感来自提示。考虑生成文本描述的任务描述数据表的任务,如图1所示,其中任务输入是一个线性化的表格(例如,“name: Starbucks | type: coffee shop”),输出是一个文本描述(例如,“Starbucks serves coffee.”)。前缀微调在输入前附加一系列连续的任务特定向量,我们称之为前缀,在图1(底部)中用红色块表示。对于后续的标记,Transformer可以像关注一系列“虚拟标记”一样关注前缀,但与提示不同的是,前缀完全由自由参数组成,这些参数不对应于实际的标记。与图1(顶部)中的微调相比,后者更新所有Transformer参数并因此需要为每个任务存储一个调整后的模型副本,前缀微调仅优化前缀。因此,我们只需要存储一个大型Transformer的一个副本和一个学习到的任务特定前缀,从而为每个额外的任务带来非常小的开销(例如,表格到文本任务的250K参数)。
与微调相比,前缀微调是模块化的:我们训练一个上游前缀来引导下游LM,而下游LM保持不变。因此,单个LM可以同时支持许多任务。在个性化上下文中,任务对应于不同的用户(Shokri和Shmatikov,2015;McMahan等人,2016),我们可以为每个用户训练一个单独的前缀,只基于该用户的数据,从而避免数据交叉污染。此外,基于前缀的架构使我们能够在单个批次中处理来自多个用户/任务的示例,这是其他轻量级微调方法无法实现的。
我们在表格到文本生成任务上使用GPT-2评估前缀微调,并在摘要任务上使用BART进行抽象总结。在存储方面,前缀微调比微调少存储1000倍的参数。在性能方面,当在完整数据集上训练时,前缀微调和微调在表格到文本任务上表现相当(§6.1),而前缀微调在摘要任务上表现出轻微的性能下降(§6.2)。在低数据设置下,前缀微调在两个任务上平均优于微调(§6.3)。前缀微调还更好地推广到具有未见过主题的表格(用于表格到文本)和文章(用于摘要)(§6.4)。
2 相关工作
等,2020;Zhu等人,2020;Liu等人,2020)。在本文中,我们专注于使用GPT-2的表格到文本任务和使用BART的摘要任务,但前缀微调可以应用于其他生成任务和预训练模型。
轻量级微调
轻量级微调冻结了大部分预训练参数,并用小型可训练模块修改预训练模型。关键挑战是识别模块的高性能架构和要调整的预训练参数子集。一条研究路线考虑移除参数:通过在模型参数上训练一个二进制掩码来消除一些模型权重(Zhao等人,2020;Radiya-Dixit和Wang,2020)。另一条研究路线考虑插入参数。例如,Zhang等人(2020a)训练了一个“侧”网络,该网络通过求和与预训练模型融合;适配器微调在预训练LM的每一层之间插入任务特定层(适配器)(Houlsby等人,2019;Lin等人,2020;Rebuffi等人,2017;Pfeiffer等人,2020)。与这条工作路线相比,该路线调整了大约3.6%的LM参数,我们的方法在保持相当性能的同时,将任务特定参数进一步减少了30倍,仅调整了0.1%。
提示
提示意味着在任务输入前附加指令和一些示例,并从LM生成输出。GPT-3(Brown等人,2020)使用手动设计的提示来适应其生成以应对不同任务,这种框架被称为上下文学习。然而,由于Transformer只能基于有限长度的上下文进行条件化(例如,GPT-3的2048个标记),因此上下文学习无法充分利用比上下文窗口更长的训练集。Sun和Lai(2020)还通过关键词提示来控制生成句子的情感或主题。在自然语言理解任务中,提示工程在先前的工作中已被用于像BERT和RoBERTa这样的模型(Liu等人,2019;Jiang等人,2020;Schick和Schütze,2020)。例如,AutoPrompt(Shin等人,2020)搜索一系列离散的触发词,并将其与每个输入连接起来,以从掩码LM中引出情感或事实知识。与AutoPrompt不同,我们的方法优化了连续的前缀,这些前缀更具表现力(§7.2);此外,我们专注于语言生成任务。
连续向量已被用于引导语言模型;例如,Subramani等人(2020)表明,预训练的LSTM语言模型可以通过为每个句子优化一个连续向量来重建任意句子,使向量输入特定。相比之下,前缀微调优化了一个适用于该任务所有实例的任务特定前缀。因此,与之前的应用仅限于句子重构的工作不同,前缀微调可以应用于NLG任务。
可控生成
可控生成旨在引导预训练的语言模型以匹配句子级别的属性(例如,关于体育的积极情感或主题)。这种控制可以在训练时发生:Keskar等人(2019)预训练语言模型(CTRL)以基于元数据如关键词或URL进行条件化。此外,控制可以在解码时通过加权解码(GeDi,Krause等人,2020)或迭代更新过去的激活(PPLM,Dathathri等人,2020)来实现。然而,没有直接的方法将这些可控生成技术应用于生成内容的细粒度控制,这是表格到文本和摘要等任务所要求的。
3 问题陈述
考虑一个条件生成任务,其中输入是一个上下文x,输出y是一系列标记。我们关注两个任务,如图2(右)所示:在表格到文本任务中,x对应于线性化的数据表,y是文本描述;在摘要任务中,x是一篇文章,y是一个简短的摘要。
3.1 自回归LM
假设我们有一个基于Transformer架构(Vaswani等人,2017)的自回归语言模型pφ(y | x)(例如,GPT-2;Radford等人2019)并由φ参数化。如图2(顶部)所示,令z = [x; y]为x和y的连接;令X_idx表示对应于x的索引序列,Y_idx表示对应于y的索引序列。
时间步i的激活是h_i ∈ ℝ^d,其中h_i = [h_i^(1); … ; h_i^(n)]是此时间步所有激活层的连接,而h_i^(j)是时间步i时第j个Transformer层的激活。1
自回归Transformer模型将h_i计算为z_i和其左上下文中的过去激活的函数,如下所示:
其中最后一层的h_i用于计算下一个标记的分布:,W_φ是一个预训练矩阵,将h_i^(n)映射到词汇表上的对数几率。
3.2 编码器-解码器架构
我们还可以使用编码器-解码器架构(例如,BART;Lewis等人,2020)来建模p_φ(y | x),其中x由双向编码器编码,解码器自回归地预测y(基于编码的x及其左上下文)。我们使用相同的索引和激活符号,如图2(底部)所示。对于所有i ∈ X_idx,h_i由双向Transformer编码器计算;对于所有i ∈ Y_idx,h_i由自回归解码器使用相同的方程(1)计算。
3.3 方法:微调
在微调框架中,我们用预训练参数φ初始化。这里p_φ是一个可训练的语言模型分布,我们对以下对数似然目标进行梯度更新:
max_φ log p_φ(y | x) = ∑{i∈Y_idx} log p_φ(z_i | h<i). (2)
4 前缀微调
我们提出前缀微调作为条件生成任务微调的替代方案。我们在§4.1中首先提供直觉,然后在§4.2中正式定义我们的方法。
h_i^{n}由一个键值对组成。在GPT-2中,每个键和值的维度都是1024。
4.1 直觉
基于提示的直觉,我们认为拥有适当的上下文可以在不改变其参数的情况下引导LM。例如,如果我们希望LM生成一个词(例如,Obama),我们可以在其前附加常见的搭配作为上下文(例如,Barack),LM将为所需的词分配更高的概率。将这种直觉扩展到生成单个词或句子之外,我们希望找到一个能够引导LM解决NLG任务的上下文。直观上,上下文可以通过指导从x中提取什么来影响x的编码;并通过引导下一个标记分布来影响y的生成。然而,是否存在这样的上下文并不明显。自然语言任务指令(例如,“用一句话总结以下表格”)可能会引导专家注释者解决任务,但对于大多数预训练LM来说可能失败。[2] 数据驱动的离散指令优化可能会有所帮助,但离散优化在计算上具有挑战性。
与其在离散标记上进行优化,我们可以将指令优化为连续的词嵌入,其效果将向上传播到所有Transformer激活层,并向右传播到后续标记。这比需要匹配真实词嵌入的离散提示更具表现力。同时,这不如干预所有激活层(§7.2)那么具有表现力,后者避免了长程依赖并包含更多可调参数。因此,前缀微调优化了前缀的所有层。
[2] 这里指预训练模型可能无法直接理解或有效响应自然语言指令,需要进一步的调整或优化才能达到预期效果。
4.2 方法
前缀微调为自回归LM添加一个前缀以获得,或者为编码器和解码器都添加前缀以获得,如图2所示。这里,表示前缀索引序列,我们用表示前缀的长度。
我们遵循方程(1)中的递归关系,只是前缀是自由参数。前缀微调初始化一个可训练矩阵(由θ参数化),其维度为,用于存储前缀参数。
训练目标与方程(2)相同,但可训练参数集发生变化:语言模型参数φ固定不变,前缀参数θ是唯一的可训练参数。
在这里,(对于所有)是可训练的的函数。当时,这是显而易见的,因为直接从复制。当时,仍然依赖于,因为前缀激活始终在左上下文中,并因此会影响其右侧的任何激活。
4.3 P_θ的参数化
经验上,直接更新参数会导致优化不稳定和性能略有下降。[3] 因此,我们重新参数化矩阵,通过较小的矩阵(P’_θ)与大型前馈神经网络(MLP_θ)组合而成。注意P_θ和P’_θ具有相同的行数…
[3] 这里指直接更新前缀参数可能导致训练过程不稳定,影响模型的最终性能,需要采用更稳健的方法来优化这些参数。
BitFit
最早2021年提出,ACL 2022
非常简单,其不需要对预训练模型做任何改动,只需要指定神经网络中的偏向(Bias)为可训练参数即可
LoRA
Low-Rank Adaptation of Large Language Models(2021,ICLR)
传统微调在微调大型预训练模型(如GPT-3、T5)时,通常需要更新所有参数(全参数微调)。
能否仅更新少量参数即可适配下游任务?
背景:适配器方法
核心思想
低秩假设:模型在适配新任务时,参数变化量(ΔW)具有低秩性质(即ΔW可以被分解为两个小矩阵的乘积)。
冻结原始参数:保持预训练模型的权重矩阵 W 固定,仅训练一个低秩的适配器(Adapter)来近似ΔW。 其中 B ∈ ℝ^{d×r} 和 A ∈ ℝ^{r×k} 是低秩矩阵(r ≪ min(d,k)),r 是秩(rank)。
在Transformer中的应用
-
目标层:通常应用于Transformer中的 注意力投影矩阵(如Q、K、V的投影矩阵)和 前馈网络(FFN)的权重矩阵。
-
参数注入方式:
- 对原始权重矩阵 W,添加旁路分支 B A。
- 前向传播时,输出为原始权重结果与低秩适配结果的叠加: 其中α是缩放系数(超参数),用于控制适配强度。
-
训练阶段:仅优化低秩矩阵 B 和 A,原始权重 W 保持冻结。
-
推理阶段:
- 可将 W + B A 合并为一个新矩阵,不增加额外计算量。
- 支持多任务适配:通过切换不同的 B A 组合适配不同任务。
超参数选择
- 秩(r):控制低秩矩阵的维度(通常 r=8 或 r=16 已足够)。
- 适配位置:选择哪些层的权重矩阵添加LoRA(例如仅适配注意力层)。
- 缩放系数α:平衡原始权重与适配权重的贡献。
参数效率
假设对L个权重矩阵应用LoRA,每个矩阵维度为d×k,则总参数量为 L × r × (d + k)。对于GPT-3(175B参数),若对注意力层的96个矩阵应用LoRA(r=8),总训练参数量仅约 0.1M,是全参数量的一千万分之一。
优势
内存占用低、部署灵活、性能接近全微调
进阶技术
- QLoRA:结合量化(Quantization)与LoRA,进一步减少显存占用。
- AdaLoRA:动态调整秩(r)和适配位置,提升参数效率。
- 组合其他PEFT方法:与Prompt Tuning或Adapter结合,实现多级适配。
多模态扩展
- 图像-文本模型(如CLIP):可对视觉编码器和文本编码器分别应用LoRA。
- 多任务学习:共享部分LoRA参数,同时适配多个任务。
Prompt-tuning
参考资料:五万字综述!Prompt-Tuning:深度解读一种新的微调范式 - 知乎(部分内容并不正确)
初步认识
特点:不更新预训练模型本身的参数!让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果。这是怎么做到的?
我们从Bert的tuning开始!
假设下游任务是预测该句子是积极的(positive)还是消极的(negative)给定一个句子[CLS] I like the Disney films very much. [SEP]
传统的Fine-tuning方法是将其通过BERT的Transformer获得 [CLS]表征之后再喂入新增加的MLP分类器进行二分类,需要一定量的训练数据来训练。
而Prompt-Tuning则执行如下步骤:
- 构建模板(Template Construction) :通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
[MASK]标记的模板。例如It was [MASK].,并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器(在huggingface中为BertForMaskedLM),即可直接得到[MASK]预测的各个token的概率分布; - 标签词映射(Label Word Verbalizer):因为
[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。
可以想到,不同的句子适合的template和label word映射应该都不同,这是Prompt-tuning非常重要的挑战。
- 训练 :根据Verbalizer,则可以获得指定label word的预测概率分布,采用交叉信息熵进行训练。此时只对预训练好的MLM head进行微调。
历程 (ICL & PET)
Prompt-Tuning起源于GPT-3的提出
《Language Models are Few-Shot Learners》(NIPS,2020)
In-context Learning(ICL):直接通过从训练集中挑选一些训练样本作为任务的提示提示(Natural Language Prompt),来实现免参数更新的模型预测。
Translate English to French:sea → mersky → cielcheese → fromagedog →给定一个训练集 和一个测试集 (因为ICT不涉及参数更新,所以一般情况下无需验证集),给定该任务的指令模板 ,给定一个预训练模型。从训练集中采样k个训练样本 (称作 In-Context Examples ),根据指令模板 ,将这k个训练样本进行线性拼接,得到一个上下文模板( 称作Demonstration )
给定一个测试样本 ,将其与模板拼接喂入模型中进行预测即可。
当执行分类时,此时需要对生成的结果进行映射,例如通过Verbalizer的方法,获得Label Word生成的概率。
但做这种简单的提示在小模型上效果不会太好。
因此,大名鼎鼎的PET模型问世——
PET(Pattern-Exploiting Training)
《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL,2021)
借鉴了上面的思想,但在普通的预训练模型上也能用!不一定非要GPT3那种大模型!
PET详细地设计了Prompt-Tuning的重要组件:Pattern-Verbalizer-Pair(PVP)
- Pattern :即上文提到的Template,为额外添加的带有
[mask]标记的短文本 - Verbalizer:Verbalizer的构建需要取决于对应的Pattern 上述两个组件被称为Pattern-Verbalizer-Pair(PVP)
PET还提出了Prompt-Tuning的集成,如同一个句子设计多个不同的pattern,每个Pattern又对应多个label word。
PET还提供了半监督的学习方法——iterative PET(iPET)
更多角度理解
Prompt本质上是对下游任务的指令,可以作为一种信息增强 。
看似设计指令是一件容易的事情,但是在真实使用过程中,预训练模型很难“理解”这些指令,主要因为预训练模型不够大、模型缺乏指令相关的训练。
后者似乎可以用上文提到过的head的再训练解决,但我们期望预训练模型还应该在未知的指令上具备一定的泛化性能。
为了达到这个目的,最常用的方法是 元学习(Meta Learning),也就是Meta Prompt Tuning(MPT),几个代表性的工作:
- 《TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification》:代表方法TransPrompt,利用迁移学习提升预训练语言模型在不同类型任务上的泛化性能;
- 《Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections》:代表方法:MPT,统一分类任务范式,并采用元学习进行训练;
Prompt Tuning的本质是复用预训练语言模型在预训练阶段所使用的目标和参数 。
实现基于Prompt的统一范式。
充分利用这个思想的方法:
- 万物皆可生成 :将所有任务统一为文本生成,极大化利用单向语言模型目标;
- 万物皆可抽取 :将所有任务统一为抽取式阅读理解,并设计抽取式预训练目标;
- 万物皆可推理 :将所有任务建模为自然语言推断(Natural Language Inference)或相似度匹配任务。
Prompt Tuning是一种PEFT
参数有效性学习过程中,大模型中只需要指定或额外添加少量的可训练参数,而其余的参数全部冻结,这样可以大大提高模型的训练效率的同时,确保指标不会受到太大影响。
常见经典的参数有效性学习有Adapter-Tuning(2019)、Prefix-Tuning、BitFit。
关于In-Context的更多
-
样本的Input-Output Mapping的正确性是否对ICL有何影响?
两个来自EMNLP2022针对样本挑选的分析型工作:
-
《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》(简称 Rethinking)
-
《Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations》(简称 Ground-Truth)
研究发现使用Demonstration比不使用的效果好,random label对模型性能的破坏并不是很大。宁愿错的map也比没有Demonstration好。换言之。ICL的性能收益主要来自独立规范的输入空间和标签空间,以及正确一致的演示格式。
-
In-Context Example的选择与顺序对ICL有什么影响?有工作发现,随机采样的方法会面临方差大的风险。
来自ACL2022的两个经典工作:
- 《What Makes Good In-Context Examples for GPT-3?》:代表方法KATE;
- 《Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity》:简称Fantastically
一些ICL的改进工作:
-
引入自监督(Self-supervised ICL)
-
统一范式+元学习(MetaICL)
-
对预测进行矫正(Calibrate Before Use)
Instruction-tuning
指令学习
假设是一个Question Generation任务,那么可以为这个任务定义一些指令,例如:
- Title:任务的名称;
- Definition:任务的定义,说明这个任务的本质和目的;
- Things to avoid:说明这个任务的注意事项,例如需要避免什么等等;
- Positive / Negative Examples:给出正确和错误的例子,作为提示;
- Prompt:当前任务的提示信息;
当许多任务都按照这种模式定义好模板,让模型在指令化后的数据上进行微调,模型将可以学会如何看到指令做预测。
感觉思想上和Prompt tuning一样?只不过这个模板更加复杂精确规范了?还有就是它是针对大语言模型的微调,做法上更像是SFT,只不过训练格式统一了instruction的形式。
FLAN
《Finetuned Language Models are Zero-shot Learners》
Finetuned Language Net,Google,2021
基于Instruction-Tuning
目标是改善GPT3的zero-shot效果
62个NLP任务转化为自然语言指令格式,进行多任务训练,每个任务都设计了Instruction,最后得到137B的大模型
关于多模态
CLIP
Contrastive Language–Image Pretraining(2021,OpenAI)
预训练模型 多模态
核心
-
跨模态对齐:将图像和文本映射到共享的语义空间中,使得同一语义的图文对在嵌入空间中距离更近,不相关的图文对距离更远。
-
零样本能力:无需针对下游任务进行微调,直接通过自然语言描述完成图像分类、检索等任务。
CLIP由两部分组成:
- 图像编码器(Image Encoder)
- 使用CNN(如ResNet)或Vision Transformer(ViT)提取图像特征。
- 将输入图像转换为固定维度的特征向量(例如512维)。
- 文本编码器(Text Encoder)
- 使用Transformer架构(类似BERT)处理文本。
- 将文本序列转换为固定维度的特征向量(与图像编码器输出维度一致)。
CLIP的训练依赖于对比学习(Contrastive Learning),其核心思想是通过最大化正样本对的相似度、最小化负样本对的相似度来优化模型参数。
使用互联网上的大规模图文对数据(如OpenAI使用的4亿对数据)每个样本对包含一张图像和一段描述该图像的文本。
-
特征提取
- 图像编码器提取图像特征 。
- 文本编码器提取文本特征 。
-
相似度计算
- 计算图像特征与文本特征的余弦相似度:
-
对比损失函数
-
使用InfoNCE损失函数(Noise Contrastive Estimation的变体):
- 为温度参数(控制分布平滑程度)。
- 为负样本数量(通常从其他文本或图像中随机选取)。
-
-
双向优化
- 同时优化图像到文本和文本到图像的匹配(双向交叉熵损失)。
CLIP最显著的特性是零样本分类(Zero-shot Classification)。其原理如下:
-
传统方法:需要针对每个类别进行有监督训练(如ImageNet分类任务需要标注数据)。
-
CLIP的方法:
-
输入一张未见过的图像 。
-
生成多个文本描述 (如“dog”、“cat”、“car”)。
-
计算图像与每个文本描述的相似度,选择相似度最高的文本作为预测类别。
无需针对特定类别进行训练。可动态扩展类别(只需提供新的文本描述)。
-
开源项目:
- 官方实现:https://github.com/openai/CLIP
- 社区改进:如
open_clip、clip-interrogator(图像到文本生成)。
复现CLIP
- 使用Hugging Face库加载预训练CLIP模型(如
clip-vit-base-patch32)。 - 实现零样本分类任务(如对ImageNet子集进行测试)。
BLIP
Bootstrapping Language-Image Pre-training(Saleforce Research,2022)
核心思想:通过数据增强、Bootstrapping解决噪声数据问题,同时支持理解与生成任务。
多模态混合编码器-解码器架构:包含图像编码器(ViT)、文本编码器(BERT)和文本解码器(GPT),支持灵活的任务切换(如视觉问答、图像描述生成)。
Caption Filtering & Rewriting:利用模型自身生成高质量图文对,清洗噪声数据,类似生物学中通过转录组筛选差异表达基因(DEGs)优化关键通路分析。
集成ITM(Image-Text Matching)、ITC(Image-Text Contrastive Learning)、MLM等任务,提升多任务泛化能力。
ALBEF
Align Before Fuse(微软,2021)
强调模态对齐(Image-Text Contrastive Learning)作为多模态融合的前提,通过对比学习拉近图像与文本的嵌入空间距离,再通过跨模态注意力实现特征融合。
- 动量蒸馏:利用动量模型生成伪标签,缓解噪声数据(如网络爬取的图文对)对训练的干扰。
- 多任务联合训练:结合ITM、ITC、MLM
- 轻量级设计:仅需单流架构(ViT+BERT),计算效率高于双流模型。
Flamingo
Flamingo(DeepMind, 2022)
首个支持少样本学习的多模态模型,通过冻结预训练视觉与语言模块,插入可训练交叉注意力层实现高效适配
- Perceiver Resampler:将视觉特征压缩为固定长度的token序列,解决多图像/视频输入的长序列问题。
- 上下文少样本学习:类似生物学中通过环境动态调控藻酸盐结构(如季节变化对M/G比例的影响),模型能根据少量示例动态调整输出策略。
- 大规模多模态预训练:融合45M图文对和30M视频文本数据,覆盖开放域任务。
多模态大模型的初步认识
多模态大模型(Multimodal Large Language Model,MMLLM)
基本组成
1.1 模态编码器(Modal Encoder)
如CLIP的ViT(Vision Transformer)
1.2 模态接口(Modal Interface)
连接不同模态的编码器与语言模型(LLM),解决模态间的对齐问题。
- 跨模态注意力机制:通过Transformer的多头注意力机制,将不同模态的特征进行交互。例如,CLIP中的图文对齐通过交叉注意力实现。
- 特征融合策略:如早期融合(在编码阶段融合)、晚期融合(在决策阶段融合)或混合策略。
- 模态适配器(Adapter):在LLM中插入轻量级适配层(如LoRA),使模型能够处理多模态输入。
1.3 生成器(Generator)
- Image Captioning
- Text-to-Image
- 跨模态检索,根据文本搜索相关图像,或根据图像搜索相关文本。
核心技术
2.1 数据对齐(Data Alignment)
不同模态的数据在语义空间中存在异质性(如图像的连续空间 vs. 文本的离散空间)。
- 预训练对齐:通过大规模图文对数据(如CLIP使用的4亿对数据)训练模型,使不同模态的嵌入空间对齐。
- 动态对齐:在推理时通过注意力机制动态调整模态间的关系(如多模态Transformer)。
2.2 数据融合(Data Fusion)
- 特征级融合:将不同模态的特征拼接或加权平均。
- 决策级融合:在最终决策阶段结合各模态的结果(如投票机制)。
- 跨模态交互:通过Transformer的交叉注意力机制实现模态间的深层次交互。
2.3 统一标识空间(Unified Representation Space)
构建一个共享的语义空间,使得不同模态的数据能够映射到同一空间中进行比较或操作。
如CLIP的嵌入空间:通过联合训练,使文本和图像的嵌入向量在同一个空间中对齐。
下游任务
视觉问答(Visual Question Answering,VQA)
模型根据输入的图像和文本问题生成答案。
例如,Monkey模型通过反向思维链推理(Backward Chain of Thought)提升复杂问题的解题能力。
图文生成(Image-to-Text / Text-to-Image)
- 典型模型:
- Text-to-Image:Stable Diffusion、DALL-E、Midjourney。
- Image-to-Text:CLIP、BLIP、InstructBLIP。
- 技术突破:
- 扩散模型(Diffusion Models):通过逐步去噪生成高质量图像。
- 指令微调(Instruction Tuning):通过RLHF或LoRA优化模型对复杂指令的理解能力。
Spatial Visual Reasoning(空间视觉推理)
例如,判断一个物体是否在另一个物体的上方
Visual Commonsense Reasoning(视觉常识推理)
视觉常识推理要求模型不仅能够识别图像中的物体,还需要理解这些物体之间可能存在的复杂关系,并基于常识进行推理。比如,给出一张图片,模型需要回答“为什么图中的男生正在指着女生”
Referring Expression Comprehension(指代表达理解)
指代表达理解是指给定一段描述性的文本(如句子),模型需要在一幅或多幅图中找到被这段文本所描述的具体对象。这项任务挑战了模型对自然语言的理解能力以及将语言与视觉信息关联的能力。例如,给定句子“穿红色衣服的女孩旁边有一只黑狗”,模型需要准确地在图片中定位出这个女孩和这只狗。
Image-Text Retrieval(图文检索)
根据文本查询来检索相关联的图像,或者反过来,根据图像来检索相关的文本描述。